



Enter your email address to stay up to date on new releases
.png)
.png)
TRAM (Tax Review and Assessment Model) is Sphere’s AI-native tax research system for global indirect tax. It automatically ingests and interprets legislative and administrative guidance, builds product taxonomies, and determines taxability, rates, and sourcing rules across jurisdictions.
TRAM enables rapid expansion into new products and regions while maintaining high accuracy through expert-in-the-loop review and continuous feedback.
Introduction
At the core of any tax compliance company is its tax engine. This engine takes in information about a transaction and outputs the applicable taxes. This sounds like a simple task, however there are many variables the tax engine must consider to respond correctly, and these variables are constantly changing. The engine must know, for every product type, how that product is taxed in every supported jurisdiction over time.
The process of determining how a product is taxed in a jurisdiction requires the continuous examination of that region’s legislation, administrative guidance, case law, and private letter rulings. It is a complex process that traditionally has required companies to hire large teams of tax experts (or ‘content’ teams) that spend countless hours reviewing each jurisdiction’s rules and rates, codifying what eventually becomes the tax engine’s internal rules. This process has been labor intensive, costly and prone to error. It has been the major inhibitor to expansion into new jurisdictions and product types for incumbents in the space.
Sphere has taken a different approach to this problem, an AI native tax engine, powered by our Tax Review and Assessment Model (TRAM).
TRAM, a system of models, operates like a tax researcher, sifting through all of the applicable tax law for a region and determining how each product type is taxed.
It tackles each part of the tax research process, from:
- Determining product class taxonomies that account for all the taxable characteristics of a product.
- Generating tax determinations for each distinct product characteristic combination in every region, and
- Sourcing applicable rates and reduced rates.
It also continues to monitor the data sources that informed its determinations, to ensure that as laws and guidance change in jurisdictions we are always in sync with the jurisdictions most up-to-date rules.
TRAM has unlocked the ability for us to provide universal coverage, any product type in any region around the world, as well as automated monitoring to ensure our treatment is always up to date.
The model’s outputs are still reviewed by our internal tax experts before being pushed into our live tax engine, but TRAM has created a step change in speed and accuracy over traditional manual research processes.
And the model is built to improve over time. Any correction that is made to its outputs are given an explanation and fed back into the model to inform future decisions, resulting in a self-improving system.
A description of how TRAM operates is given below, as well as a discussion of the results we’ve seen thus far, and where we plan to take TRAM in the future.
System overview and architecture
At a high level, TRAM sits between the global corpus of tax authority materials and Sphere’s deterministic tax engine. Its job generally is to turn unstructured legislative and administrative content into versioned, machine readable rules that can safely drive tax calculations.
The system follows the same basic steps a human tax researcher would, but at a different scale
- Ingestion: Our web automation systems continuously ingest and monitor statute law, regulations, guidance, bulletins, case law, and private letter rulings.
- Data normalization and preparation: These materials are normalized, split into semantically meaningful sections using a combination of rules based and LLM powered splitting, and enriched with metadata such as jurisdiction, authority type, effective dates, and document hierarchy.
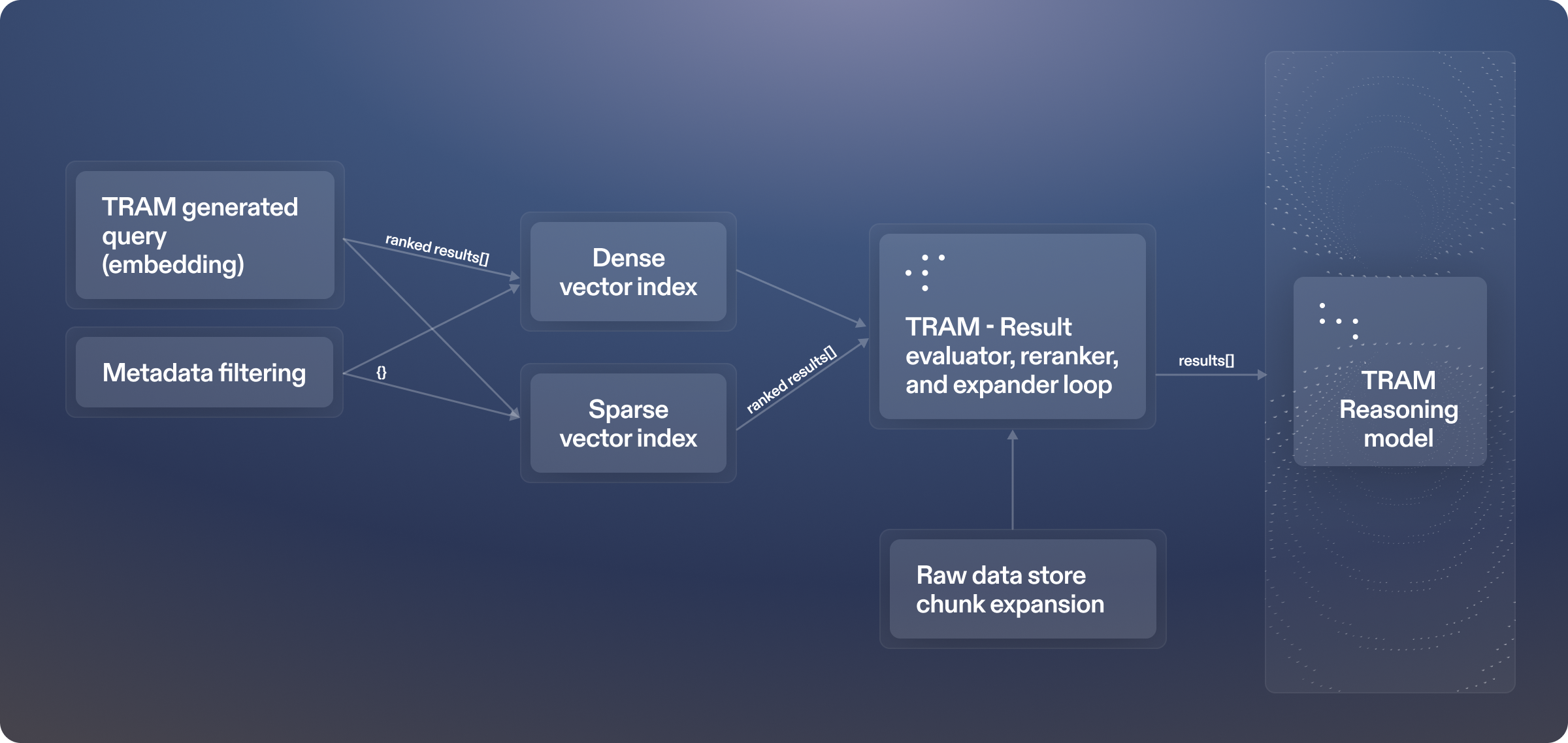
- Indexing: Each section is then indexed in both dense and sparse form, forming a hybrid retrieval layer that TRAM queries for a specific task.
- Reasoning: Given a task description, product and jurisdiction context, and the retrieved authorities, TRAM uses RFT reasoning models to propose a determination or taxonomy with an accompanying reasoning summary and backing citations.
- Review: Each of these proposals flow into a review portal where Sphere’s tax experts approve, or modify TRAM’s outputs. Approved results are converted into versioned rules and promoted into the production tax engine, while the expert feedback is fed back into TRAM to improve future retrieval and reasoning.
Collecting and monitoring relevant data sources
The same as a human tax researcher, TRAM’s reasoning must be grounded in the controlling authority for each jurisdiction. Doing this correctly requires familiarity with and ongoing review of the relevant sources as part of the research process for a particular product or service.
To give TRAM this same access to data, we have built web automations that collect the authoritative sources of tax information for every jurisdiction. This includes primary statute law, administrative regulations and guidance, bulletins and notices, case law, and private letter rulings. Wherever possible, these materials are collected directly from official government and tax authority websites so that TRAM is working only from authoritative sources.
We leverage our home grown web automation tool, WARP (Web Automation Reimagined Purposefully), to collect and maintain this corpus. WARP tracks where each source is published and schedules recurring crawls. When an authority is updated or a new document is released, WARP detects the change and triggers re-ingestion through the data pipeline of this raw data. This allows TRAM to reason over a corpus that is both comprehensive and monitored over time, and to tie its determinations back to the underlying authority via citations.
As sources are modified over time by the legislature or the authority’s Department of Revenue releases new guidance and precedence, TRAM will not only collect this data but also begin a review of our determinations based on those authorities and flag updates that need to be made to our human experts for approval.
This ensures that we are always proactive in getting updates made due to tax authority changes rather than reactive once the change is already live and effective.
.png)
Data normalization and preparation
The raw data collected by TRAM must undergo several steps before it is ready to be indexed. Our sources are varied. They include web pages, PDFs, spreadsheets, and word documents. The first task is to extract the content while preserving as much of the original structure as possible. In practice, this means that web pages retain their HTML tags at this stage so that their structure is still present, and structured PDFs are kept intact rather than being flattened into plain text.
Once we have the raw structured data, each document must be prepared for indexing into our hybrid vector and full text search indexes. Many of these documents are very large. They cannot simply be indexed as a single document, so the content must be broken into smaller, semantically meaningful pieces.
This splitting step is a critical part of our ingestion pipeline, and we have invested significant resources in tuning it. A naive approach would be to break documents into chunks of a fixed size by splitting every N words. This has obvious downsides. It routinely cuts in the middle of important sentences or paragraphs and destroys the natural structure that a human researcher would use. There are well known attempts to mitigate this, such as adding overlapping windows between chunks, but these approaches still carry their own tradeoffs and tend to produce suboptimal results.
Legal and tax documents, however, already come with strong internal structure. They are organized into titles, chapters, sections, subsections, and paragraphs. This is what allows a human reader to quickly navigate to the relevant part of a statute or bulletin. TRAM is built to exploit this structure directly.
We have implemented two systems to determine where and how to split a document into its natural parts. The first is a rules based system that encodes the patterns we see most often in tax authority materials. It identifies headings, numbering schemes, and other structural markers to infer the boundaries of sections and subsections. When its rules are met, this system is extremely accurate and fast.
Of course, real world documents are messy and not all of them follow a single consistent pattern. That is where the second LLM-powered system comes in. This component analyzes documents that do not fit neatly into our rules and learns how to generate document specific splitting rules. It builds bespoke rules based splitting strategies that are tailored to the structure of the target document, and can then be applied in code.

The result of these efforts is that we can split documents into their natural sections that fit within our indexing parameters with much higher accuracy to the source materials structure. This part of the pipeline has been a major driver of the accuracy we have seen from TRAM in practice.
After a document has been broken into sections, we also enrich each section with metadata. This includes information about the parent document, jurisdiction, effective dates, authority type, and tags derived from the content itself. The hierarchy of the document is preserved in the metadata for each chunk by recording its parent section and allowing that relationship to be followed all the way back to the root document. For non English documents, we also store an English generated version alongside the original to make review by our internal tax experts simpler and more consistent.
Indexing
With our raw data prepped and normalized, it is ready to be indexed. Each enriched chunk is written into two different indexing systems. A dense vector index and a sparse vector index. For every chunk we generate both a dense embedding and a sparse embedding from its enriched content, and store those embeddings alongside the chunk’s metadata so they can be filtered during retrieval later. We have experimented with a number of dense embedding models, as well as different input token sizes, before settling on our current approach.
Despite recent progress in semantic embeddings, we still get a lot of value from a sparse, term based view of the corpus. Sparse retrieval is very strong at honoring the exact vocabulary, phrase boundaries, and citations that carry weight in legal materials. Dense retrieval of course is better at capturing meaning when the query and source use different wording or structure. In practice the two behave differently enough that using both in parallel consistently outperforms either one on its own.
By indexing each chunk in both dense and sparse form and keeping the same metadata attached to each, we can use hybrid retrieval strategies that combine the strengths of both approaches. This means TRAM can find the right authorities even when the query is phrased quite differently from the source language, while still being able to lock onto exact statutory phrases, definitions, and citations when that precision is required.
Retrieval steps
At retrieval time, TRAM queries both the dense and sparse indexes to find relevant sources. We first filter the index down to the target jurisdiction so that all results are scoped to the right region. TRAM then generates a search query in both sparse and dense form, based on the task it is working. In some cases this query will describe a specific product classification we want to make determinations for. In others it will describe a product type more broadly so that TRAM can find the right sources to inform the creation or refinement of a product taxonomy. In either case, the query is used to retrieve candidate sections from both the dense and sparse indexes.
Once we have candidates from both indexes, we compare and merge the results. Sections that appear in both the dense and sparse result sets are boosted. From this combined list, TRAM then enters a recursive refinement loop.
In the loop, TRAM analyzes the current set of sections in the context of the task, reranks them based on that analysis, and drops the least relevant results. For the remaining top sections, it expands the context by pulling in neighboring sections from the same source documents.
This process of retrieve, rerank, prune, and expand is repeated until we reach our target context size for the downstream reasoning step. The final output of retrieval is a curated set of sections, with their full metadata and document hierarchy attached, ready to be handed off to TRAM’s main reasoning process as its working set of authorities.
Tax reasoning and determination
At this point TRAM has all of the inputs it needs to work on a specific task. Whether TRAM is generating tax determinations for a given product type or designing a product taxonomy, the core process is the same.
For each task, TRAM is given a structured description of the objective, the target product, and the jurisdiction. This includes how the jurisdiction imposes sales tax (the imposition of tax), known subtleties and ambiguities, and any existing treatment that Sphere already applies. Alongside this, TRAM receives the curated set of authorities from the retrieval step, complete with document hierarchy, effective dates, and authority types. We also pass in signals learned from prior expert reviews for that product and jurisdiction, so that the system can avoid repeating past mistakes and can build on decisions that have already been approved.
On top of this context we use RFT reasoning models from OpenAI that we have fine tuned on our expert feedback. These models are optimized for multi step legal and tax reasoning and analyzing and weighing different legal authorities. For a determination task, TRAM reads through the retrieved authorities, interprets how they apply to the product, and then produces a structured proposal. That proposal includes taxability, applicable rates, any abatements or reductions, and sourcing and apportionment rules.
For taxonomy tasks, TRAM focuses on identifying the product characteristics that matter for tax treatment across jurisdictions. It proposes product classes and attributes, and assigns the target product into that structure.
In both cases, TRAM produces a reasoning summary that explains how it reached its conclusion and provides citations back to the underlying authorities that it derived its decision from.
The output of this stage is a complete, machine readable proposal that a human expert can review in one place. It combines the classification or determination itself, the reasoning behind it, and the specific legislative and administrative sources that support the result.
Human expert approval and feedback
TRAM is designed to act as a force multiplier for tax experts. Every determination and taxonomy proposal produced by TRAM is reviewed and approved by Sphere’s internal tax team before it is allowed into the production tax engine. The system around TRAM is an important piece of the system that we want to enable efficient expert workflow and feedback.
Once determinations or taxonomies are ready, they appear in a review dashboard used by the tax team. From this dashboard, experts can see queues of pending determination sets and taxonomy proposals, as well as alerts for existing determinations or rates that TRAM has flagged as potentially affected by new or updated guidance.
For each item under review, the expert is presented with TRAM’s proposed output alongside the reasoning summary and underlying authorities. The reviewer can approve the proposal as is, modify specific elements (for example adjusting a citation or its reasoning), or reject it and provide their own determination.
When an expert modifies or rejects a proposal, they provide a short explanation of what was wrong or was missing. These explanations are stored along with the full context of the task, the retrieved authorities, and the final approved outcome. TRAM uses this feedback to refine its retrieval and reasoning strategies for similar future tasks, and to update the supervised datasets used during the fine tuning of the underlying models.
The review portal also allows experts to mark certain determinations as part of our internal eval set. The set is run automatically whenever we make changes to TRAM’s models or retrieval pipeline. This gives us a consistent way to detect regressions, and decide whether a new version of TRAM is ready to be promoted. As well as mark our accuracy and progress on a target over time.
Once a determination is set or taxonomy has been approved, it is pushed into Sphere’s deterministic tax engine. Effective dates are handled explicitly. If TRAM has identified an upcoming legislative change that takes effect several months in the future, the expert can review and approve the new treatment today and schedule it to become active on the effective date.
We have invested heavily in the tooling around this process to keep expert time focused on judgment and feedback instead of monotonous data entry tasks. The portal supports bulk actions for related determinations, filtering and search across jurisdictions and product categories, and side by side comparisons between current and proposed treatments.
.png)
Results
We measure TRAM’s performance along two main axes, accuracy and expert time spent per determination. For our purposes, TRAM’s “accuracy” is defined as the share of determinations that do not require any edit by an expert.
Over time, TRAM’s accuracy has grown to over 90 percent, meaning fewer than 10 percent of determinations need any intervention from the reviewing expert.
This directly feeds into the second metric. As fewer items require edits, review time drops. We’ve recently crossed the single digit second mark for median review time per determination. In other words, the median time an expert spends reviewing a determination is now under 10 seconds.
Comparing our results over time, we started with an initial version of TRAM that used off the shelf models and a standard RAG setup. This initial version yielded accuracy under 65 percent and a median expert review time close to two minutes per determination.
Since then, accuracy has improved by ~40 percent, to over 90 percent, while median review time has dropped by ~92 percent, from nearly 120 seconds to under 10 seconds per determination.
This combination of high accuracy and low review time has unlocked Sphere’s ability to support new product types and jurisdictions very quickly with a lean expert team.
Qualitatively, feedback from the expert team has been strongly positive. They are able to process far more work in the same amount of time, while avoiding much of the monotonous work that typically accompanies the determination process. TRAM and the systems around it have completely changed how the team spends its time, shifting effort from repetitive tasks to higher leverage review and oversight.

Roadmap and planned expansion
Over the coming months we plan to keep pushing TRAM’s accuracy higher, with the goal of driving expert review times even lower while maintaining the same level of control and oversight.
We are also expanding TRAM beyond sales and use tax.
The same underlying system is being extended to support input tax, withholding tax, and tariffs, so that a single research and determination pipeline can power a wider set of cross border compliance workflows.
You Might Like


.png)

Make the world
one market
End-to-end compliance automation for sales tax, VAT, and GST. 100+ regions. One platform. Built by 50 people who believe the compliance cost of every transaction should be zero.





